Suraj Atreya
Functional programming, Scala, Haskell, Distributed Systems
Data Analysis using pandas
I’ve been meaning to learn pandas for a while ever since I started looking into data analysis tools. Although I don’t have extensive experience in data analysis, I’ve been writing Scala for quite sometime. Although I love Scala and its awesome libraries, it just falls short of doing quick data analysis especially exploratory data analysis (EDA). I was fishing for a good tool to do EDA and almost all the blog posts and all the community around data science suggested R as the primary tool to do EDA. But, I decided to learn pandas anyway since I have already done Python before. I have nothing against R and I will probably learn it sometime. I have checked out RStudio and it amazed me when the first time I used. But R will have to wait.
One of the advantages of pandas is that it leverages Python the language which is pretty easy to learn. Libraries such as NumPy, SciPy, matplotlib make data analysis much more powerful by visualising complex data. NumPy, SciPy have a fast matrix operations which makes it really good for analysing larger data sets with short time. Pandas leverages the power of these libraries to provide data munging, transforming and cleaning capabilities.
Now for an example. Let’s say we wanted to use Yahoo finance’s derivatives data for analysis (Tesla). But since it is in a webpage, we want to first scrape the data and make it useful for our analysis.
from lxml.html import parse
from urllib2 import urlopen
scraped = parse(urlopen(
'http://finance.yahoo.com/q/op?s=TSLA+Options'))Once we have the data, we want to get the “calls” and “puts” table. For this we will get all the tables and by trial and error figure out the tables we need.
doc = scraped.getroot()
tables = doc.findall('.//table')
calls = tables[1]
puts = tables[2]But this data is not useful right away unless there is a way to extract the table header and table data. This step is crucial since the data is not clean and has to be cleaned before applying any machine learning algorithms or statistical models for further analysis. I have defined two helper functions “unpack” and “clean_data”. “unpack” will unpack the values and finds the string for each of the table headers or table data and returns a string. “clean_data” as the name suggests cleans any non-ascii characters and returns a parsable string.
def unpack(row, kind='td'):
elts = row.findall('.//%s' % kind)
return [val.text_content() for val in elts]
def clean_data(str):
return re.sub('[\n\s*]|[^\x00-\x7F]+','',str)To get the row header and data:
rows = calls.findall('.//tr')
rowheader_unclean = _unpack(calls, kind='th')
rowheader = []
for row in rowheader_unclean:
rowheader.append(_clean_data(row))
data_unclean = _unpack(rows[2], kind='td')
data = []
for d in data_unclean:
data.append(_clean_data(d))Putting it all together:
from pandas.io.parsers import TextParser
def parse_options_data(table):
rowheader = []
data = []
rows = table.findall('.//tr')
rowheader_unclean = unpack(table, kind='th')
for row in rowheader_unclean:
rowheader.append(clean_data(row))
data_unclean = [unpack(r) for r in rows[2:]]
for data_vals in data_unclean:
cleaned_data = [clean_data(d) for d in data_vals]
data.append(cleaned_data)
return TextParser(data, names=rowheader).get_chunk()Above we have found out which tables are calls and puts. We will just provide these tables to our newly defined function “parse_options_data”.
call_data = parse_options_data(calls)call_data should look something like as shown below:
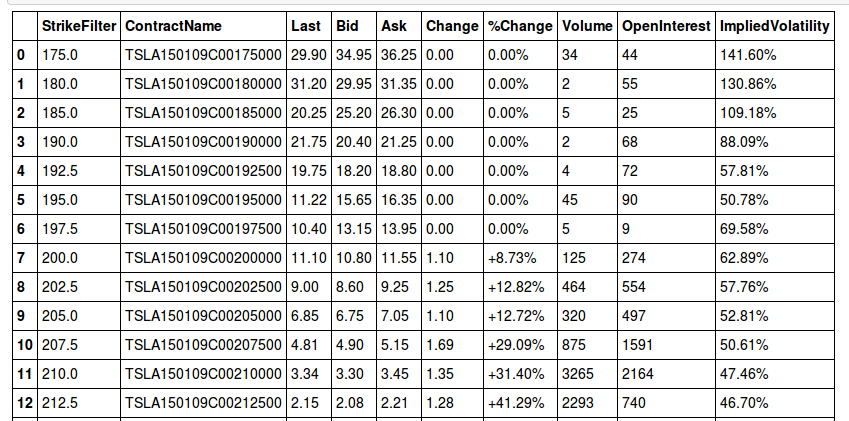
Conclusion
I found pandas to be very flexible in terms of fetching urls and parsing them with no effort. If the data were instead in a database such as MySql or someother DB, then there are many connectors available. One could connect several databases from python to analyse data from multiple sources. But for someone who is starting out pandas would be much simpler than R. Also, I haven’t shown any plotting mechanisms which I am saving it for another time. That should be more fun and hope to cover those for another day.
And, happy new year 2015 and happy hacking!
comments powered by Disqus